ICML 2026 | 打破「回音室」效应!人大孟澄团队&华为提出集成剪枝视角下的MoE新架构
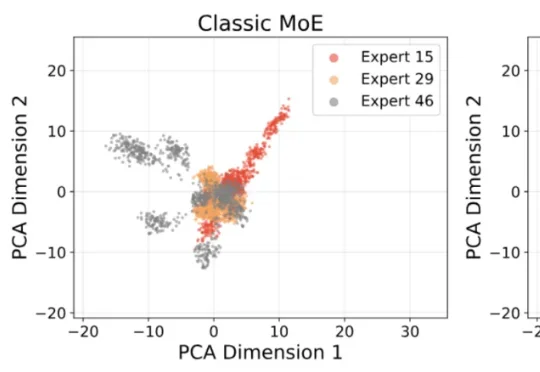
ICML 2026 | 打破「回音室」效应!人大孟澄团队&华为提出集成剪枝视角下的MoE新架构近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。
来自主题: AI技术研报
7448 点击 2026-05-23 09:56